Large Language Models: The Future of AI Text Generation
No Comments


Training Transformers at Scale using NVIDIA Megatron-LM
Megatron-LM is a powerful open-source library designed to tackle these challenges. It enables training of trillion-parameter transformer models by combining multiple forms of parallelism and highly optimized kernels.
Building a Transformer-based Language Model from scratch to generate text
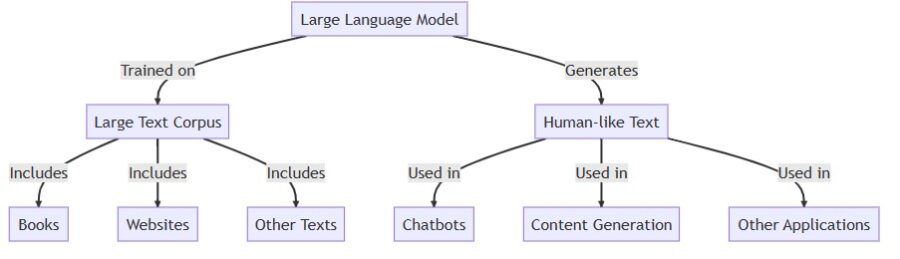
A Large Language Model (LLM) is a type of deep learning model trained on massive text datasets to understand and generate human language.

AI vs Human
Humans and artificial intelligence (AI) have been contrasted and compared frequently.Some worry that AI will drive people out of many professions, while others argue that AI will never fully replace human intelligence and creativity.